Summary of Data Structures
Summary
Yang saya pelajari pada mata kuliah Data Struct selama semester 2 ini adalah Singly Linked List, Doubly Linked List, Hash Table, Binary Tree, dan Binary Search Tree.
Singly Linked List
Adalah linked list yang hanya memiliki satu pointer menuju ke node selanjutnya.

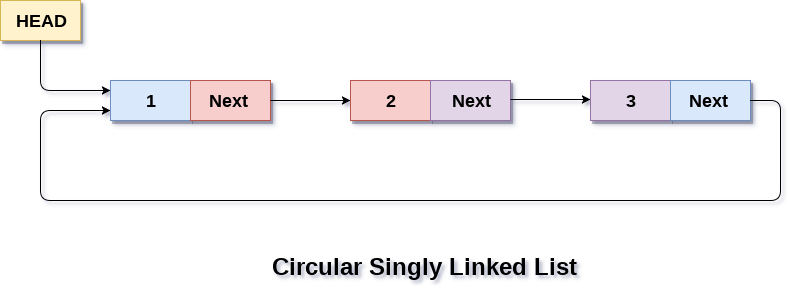
Circular Singly Linked List










Yang saya pelajari pada mata kuliah Data Struct selama semester 2 ini adalah Singly Linked List, Doubly Linked List, Hash Table, Binary Tree, dan Binary Search Tree.
Singly Linked List
Adalah linked list yang hanya memiliki satu pointer menuju ke node selanjutnya.
Adalah linked list dimana semua node terhubung oleh satu pointer next saja dan membentuk sebuah loop satu arah dan tidak memiliki NULL pada akhir dari node. Node mana saja bisa menjadi starting point karena dia hanya berhenti ketika node yang sama terulang.
Implementasi singly linked list:
struct Data{
int num;
Data *next; // pointer penunjuk node selanjutnya
}*head, *tail; // head sebagai penanda node pertama dan tail sebgai node paling ujung (terakhir)
Operasi singly linked list:
1. Push
Adalah memasukkan data baru atau node baru kedalam linked list. Terdapat 3 macam push yaitu push head, push tail, dan push mid.
// push tail : memasukkan data dari belakang
void pushB(int value){
Data *curr = (Data *) malloc(sizeof(Data)); // alokasi memori untuk node baru
curr->num = value; // memasukkan nilai dari value ke num
if(head == NULL){ // kondisi apabila linked list kosong
head = tail = curr;
}
else{
tail->next = curr; // node tail selanjutnya akan menunjuk alamat curr
tail = curr; // memindahkan tail ke curr
}
tail->next = NULL;
}
// push head : memasukkan data dari depan
void pushD(int value){
Data *curr = (Data *) malloc(sizeof(Data));
curr->num = value;
if(head == NULL){
head = tail = curr;
}
else{
curr->next = head;
head = curr;
}
tail->next = NULL;
}
// push mid: memasukkan data dari tengah dan otomatis sorting
void pushMid(int value){
Data *curr = (Data *) malloc(sizeof(Data));
curr->num = value;
if(head == NULL){
head = tail = curr;
}
else{
Data *temp = head;
while(temp->next->num < value){ // looping selama num lebih kecil dari value
temp = temp->next;
}
curr->next = temp->next;
temp->next = curr;
}
}
void push(int value){
if(head == NULL){
pushB(value);
}
else{
if(value <= head->num){ // menentukan posis data apabila lebih kecil dari
pushD(value); // head maka panggil push head dan sebaliknya
}
else if(value >= tail->num){
pushB(value);
}
else{
pushMid(value);
}
}
}
2. Pop
Adalah menghapus sebuah data dari linked list. Terdapat 4 jenis pop yaitu, pop head, pop tail, pop mid, dan pop all.
// pop head: menghapus data dari depan
void popD(){
Data *temp = head;
if(head == NULL){
return;
}
if(head == tail){
head = tail = NULL;
}
else{
head = head->next;
}
free(temp);
}
// pop tail: menghapus data dari belakang
void popB(){
Data *temp = head;
if(head == NULL){
return;
}
if(head == tail){
head = tail = NULL;
}
else{
while(temp->next != tail){
temp = temp->next;
}
free(tail);
tail = temp;
tail->next = NULL;
}
}
// pop mid: menghapus data dari tengah
void pop(int value){
Data *temp = head;
if(head == NULL){
return;
}
while(temp->num != value){
temp = temp->next;
if(temp == NULL){
return;
}
}
if(temp == head){
popD();
}
else if(temp == tail){
popB();
}
else{
Data *key = head;
while(key->next != temp){
key = key->next;
}
key->next = temp->next;
free(temp);
}
}
// pop all: menghapus semua data dalam linked list
void popAll(){
while(head != NULL){
popD();
}
}
3. Display
Adalah operasi untuk menampilkan semua data dalam linked list secara berurutan dari head sampai tail.
void display(){
Data *temp = head;
while(temp != NULL){
printf("%d\n", temp->num);
temp = temp->next;
}
}
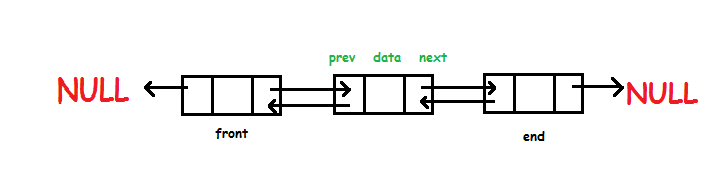
Doubly Linked List
Adalah linked list yang terdiri dari sekumpulan data yang memiliki dua tangan penghubung ke data sebelumnya dan ke data selanjutnya. Setiap ujung atau tail dari data adalah NULL dan dapat dijalankan dua arah karena memiliki dua penunjuk yaitu previous dan next. Jika kita ingin insert data atau delete data kita harus mengubah kedua pointer yang menunjuk ke data sebelum dan selanjutnya.
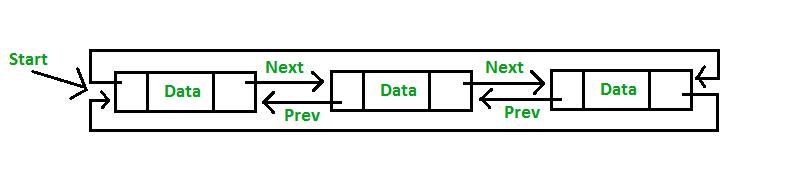
Circular Doubly Linked List
Adalah linked list yang mirip dengan Circular Singly Linked List dan Doubly Linked List dimana terdapat dua pointer yaitu previous dan next dan tidak diakhiri dengan NULL.
Implementasi doubly linked list:
secara umum doubly linked list sama dengan singly linked list, operasi nya juga sama. Sedangkan, double linked list dapat menunjuk ke data sebelumnya yang membuat berbeda adalah pada double linked list jika kita insert data atau delete data maka kita harus mengubah next dan prev, keuntungannya pada pop belakang kita bisa langsung menunjuk ke data sebelum tail tanpa harus looping lagi.
struct Data{
int num;
Data *next, *prev; // penambahan pointer prev sebagai penunjuk data sebelumnya
}*head, *tail;
void pushB(int value){
Data *curr = (Data *) malloc(sizeof(Data));
curr->num = value;
curr->next = NULL;
curr->prev = NULL;
if(head == NULL){
head = tail = curr;
}
else{
tail->next = curr;
curr->prev = tail; // node tail menunjuk ke curr, curr juga harus menunjuk tail
tail = curr;
}
tail->next = NULL;
}
void pushD(int value){
Data *curr = (Data *) malloc(sizeof(Data));
curr->num = value;
curr->next = NULL;
curr->prev = NULL;
if(head == NULL){
head = tail = curr;
}
else{
curr->next = head;
head->prev = curr;
head = curr;
}
tail->next = NULL;
}
void pushMid(int value){
Data *curr = (Data *) malloc(sizeof(Data));
curr->num = value;
curr->next = NULL;
curr->prev = NULL;
if(head == NULL){
head = tail = curr;
}
else{
Data *temp = head;
while(temp->next->num < value){
temp = temp->next;
}
curr->next = temp->next;
curr->prev = temp;
temp->next->prev = curr;
temp->next = curr;
}
}
void push(int value){
if(head == NULL){
pushB(value);
}
else{
if(value <= head->num){
pushD(value);
}
else if(value >= tail->num){
pushB(value);
}
else{
pushMid(value);
}
}
}
void popD(){
Data *temp = head;
if(head == NULL){
return;
}
if(head == tail){
head = tail = NULL;
}
else{
head = head->next;
head->prev = NULL;
}
free(temp);
}
void popB(){
Data *temp = tail;
if(head == NULL){
return;
}
if(head == tail){
head = tail = NULL;
}
else{
tail = tail->prev;
tail->next = NULL;
}
free(temp);
}
void pop(int value){
Data *temp = head;
if(head == NULL){
return;
}
while(temp->num != value){
temp = temp->next;
if(temp == NULL){
return;
}
}
if(temp == head){
popD();
}
else if(temp == tail){
popB();
}
else{
temp->prev->next = temp->next;
temp->next->prev = temp->prev;
free(temp);
}
}
void popAll(){
while(head != NULL){
popD();
}
}
void display(){
Data *temp = head;
while(temp != NULL){
printf("%d\n", temp->num);
temp = temp->next;
}
}
Hashing
Adalah data structure mengelompokkan objek dalam kelompok sama. Dalam hashing sebuah string panjang akan di ubah ke dalam key yang merupakan index pada hash table, menggunakan hash function untuk mendapatkan key tersebut. Misalnya untuk mendapatkan informasi mahasiswa kita hanya perlu NIM, karna kata kunci yang banyak maka diperlukan hashing agar lebih cepat.
Intinya Hashing adalah mentransformasi string panjang menjadi sebuah key dan index untuk mencari suatu infromasi di database.
Hash Table
Adalah array tempat kita menyimpan data sesuai index hashing.
Hash Function
- Mid-square
Dalam teknik ini untuk mendapatkan key-nya,dilakukan pangkat dua pada valuenya kemudian kita bisa mengambil nilai tengah dari hasilnya. Teknik ini memiliki kemungkinan collision yang kecil karena key yang dihasilkan cukup unik. Overflow bisa terjadi misalnya pada perpangkatan 6 digit menjadi 12 digit, maka perlu menggunakan tipe data long long int atau string.
Contoh: kita ambil 4 digit angka yaitu 1234.
Kuadrat dari 1234 adalah 1522756.
Kita ambil 4 digit tengahnya yaitu 2275 yang akan menjadi key barunya.
Langkah ini dapat dilakukan terus demi mendapatkan key yang unik.
- Division
Ini adalah teknik yang paling sering digunakan, yaitu membagi string dengan operasi modulus sesuai besar memori atau hash table yang telah ditentukan.
Contoh: diberikan ukuran hash table 5, dengan nilai 22.
Maka 22%5 = 2, dihasilkan key atau index hash tablenya 2.
- Folding
Dalam teknik ini kita memecah string per bagian kemudian ditambahkan untuk mendapatkan key-nya.
Contoh: diberikan nilai 1234.
Dipecah menjadi 12 dan 34 kemudian ditambahkan.
12 + 34 = 46, maka key nya adalah 46.
- Digit Extraction
Teknik ini mengambil digit yang sudah ditentukan menjadi keynya.
Contoh: diberikan digit 1234.
Diambil digit ke 1 dan 3 maka keynya menjadi 13.
- Rotating Hash
Teknik ini dapat menggunakan ke-4 teknik diatas, kemudian dilakukan shifting untuk mendapatkan key yang baru.
Contoh: keynya 21121 menjadi 12112 setelah di shift.
Collision
Seperti artinya yaitu tabrakan, dimana kita mau memasukkan sejumlah string tetapi ada beberapa string yang memiliki hash key yang sama. Ada 2 cara untuk mengatasi collision, yaitu:
- Linear Probing
Melakukan searching untuk mendapatkan slot selanjutnya yang kosong lalu menempatkannya disana.
- Chaining
Cara ini sama seperti konsep linked list jadi string yang memiliki hash key sama akan diletakkan pada satu slot yang sama namun saling terhubung.
Contoh implementasi hashtable menggunakan teknik divison dan chaining:
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#define TABLE_SIZE 15 // deklarasi size dari hash table
struct Data{
char key[100];
int value;
Data *next;
}*head[100]; // array hash table
Data *newData(char key[], int value){
Data *temp = (Data*)malloc(sizeof(Data));
strcpy(temp->key, key);
temp->value = value;
temp->next = NULL;
return temp;
}
int getHash(char key[]){
int hash = 0;
for(int i=0; i<strlen(key); i++){
hash += key[i];
}
return hash;
}
void put(char key[], int value){
Data *curr = newData(key, value);
int index = getHash(key) % TABLE_SIZE;
if(head[index] == NULL){
head[index] = curr;
}
else{
Data *temp = head[index];
while(temp->next != NULL){
temp = temp->next;
}
temp->next = curr;
}
}
void display(){
for(int i=0; i<TABLE_SIZE; i++){
if(head[i] != NULL){
Data *temp = head[i];
while(temp != NULL){
printf(" (%s, %d) -> ", temp->key, temp->value);
temp = temp->next;
}
printf("\n");
}
else{
printf(" ~~ \n");
}
}
printf("\n");
}
Data *get(char key[]){
int index = getHash(key) % TABLE_SIZE;
Data *temp = head[index];
while(temp != NULL && strcmp(key, temp->key) != 0){
temp = temp->next;
}
return temp;
}
int main(){
put("A", 20);
put("TEST", 15);
put("B", 10);
put("C", 25);
display();
Data *found = get("C");
if(found == NULL) printf("No data found\n");
else printf("%s %d\n", found->key, found->value);
return 0;
}
Pada implementasi diatas saya melakukan hashing dengan menambahkan ASCII dari string kemudian untuk mendapatkan keynya saya melakukan teknik divison dengan modulus sesuai ukuran hash table yang sudah ditentukan yaitu 15. Saya juga membuat kondisi collision yaitu dengan chaining, apabila dijalankan akan menampilkan A menunjuk TEST.
Bi
Adalah data structure pohon dimana memiliki dua node anak, biasanya dibedakan anatara kiri dan kanan. Node yang memiliki anak disebut parent dan node teratas disebut root.

- Full Binary Tree
Memiliki 2 child setiap node dan memiliki panjang path yang sama.

- Complete Binary Tree
Memilik 0 atau 2 child setiap node dan boleh memiliki panjang path yang berbeda.

- Skewed Binary Tree
Memiliki 1 child setiap node.
- Binary Search Tree
Memiliki data yang terurut unutk memudahkan pencarian kembali data tersebut.

Operasi pada binary tree terdiri dari:
- Create : membuat binary tree baru.
- Clear : mengosongkan binary ree.
- Empty : memeriksa kekosongan bianry treee.
- Insert : memasukkan node baru ke tree.
- Find : mencari root, parent, dan child pada tree.
- Update : mengubah isi dari node yang ditunjuk.
- Retrieve : mengetahui isi dari node yang ditunjuk.
- Delete Sub : menghapus suatu sub yang ditunjuk.
- Characteristic : mengetahui karakteristik dari tree seperti size, height, dan length.
- Traverse : menjalani masing-masing node pada tree sekali.
Keuntungan hashing adalah membandingkan dua file tanpa harus melihat isi dari file tersebut, membandingkan nilai hash yang dihitung sehingga pemilik bisa mengetahui jika mereka berbeda. Keuntungan binary tree adalah susunan data structure yang lebih baik dan searching yang cepat karena O(logn) dan bisa melakukan traverse untuk mendapatkan data yang terurut (binary search tree).
Binary Search Tree
adalah sebuah data structure binary tree yang memiliki ciri-ciri, yaitu: subtree sebelah kiri nilainya lebih kecil dari parent nodenya dan subtree sebelah kanan nilainya lebih besar dari parent nodenya.

Terdapat 3 cara dalam traverse binary tree (dilakukan secara rekursi):


- In-order
- Pre-order
- Post-order

Operasi dalam binary search tree:
1. Search : mencari data pada tree dilakukan secara rekursif. Apabila key lebih kecil dari root maka akan di rekrusif pada subtree kiri dan sebaliknya, jika tidak maka data yang dicari sudah sama.
2. Insert : mengecek apabila value yang akan di insert lebih besar dari root maka akan di rekursif ke subtree kanan dan jika lebih kecil maka di rekursif ke subtree kiri. Setelah menumakan left atau right yang kosong maka value akan di insert kesana.
3. Delete : Jika data yang mau dihapus berada pada leaf maka bisa langsung dihapus, jika data memiliki satu child maka child akan dipindah ke parentnya lalu di delete, jika data memiliki dua anak maka kita harus mencari data terbesar dari subtree kiri (predecessor) atau data terkecil dari subtree kanan (sucessor).
Berikut adalah implementasi Binary Search Tree :
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
struct Node{
int id;
char name[100];
struct Node *left, *right;
};
struct Node *createNode(int id, char name[]){
struct Node *newNode = (Node*)malloc(sizeof(Node));
newNode->id = id;
strcpy(newNode->name, name);
newNode->left = newNode->right = NULL;
return newNode;
}
struct Node *insertNode(struct Node *currNode, int id, char name[]){
if(currNode == NULL){
return createNode(id, name);
}
if(currNode->id > id){
currNode->left = insertNode(currNode->left, id, name);
}
else if(currNode->id < id){
currNode->right = insertNode(currNode->right, id, name);
}
return currNode;
}
void printInfix(struct Node *currNode){
if(currNode == NULL){
return;
}
printInfix(currNode->left);
printf("%-5d - %-20s\n",currNode->id, currNode->name);
printInfix(currNode->right);
}
void printPrefix(struct Node *currNode){
if(currNode == NULL){
return;
}
printf("%-5d - %-20s\n",currNode->id, currNode->name);
printPrefix(currNode->left);
printPrefix(currNode->right);
}
void printPostfix(struct Node *currNode){
if(currNode == NULL){
return;
}
printPostfix(currNode->left);
printPostfix(currNode->right);
printf("%-5d - %-20s\n",currNode->id, currNode->name);
}
struct Node *predecessor(struct Node *currNode){
currNode = currNode->left;
while(currNode->right){
currNode = currNode->right;
}
return currNode;
}
struct Node *deleteNode(struct Node *currNode, int id){
if(currNode == NULL){
return NULL;
}
if(currNode->id > id){
currNode->left = deleteNode(currNode->left, id);
}
else if(currNode->id < id){
currNode->right = deleteNode(currNode->right, id);
}
else{
if(currNode->left == NULL || currNode->right == NULL){
struct Node *tempNode = NULL;
if(currNode->left != NULL){
tempNode = currNode->left;
}
else{
tempNode = currNode->right;
}
if(tempNode == NULL){ // kalau tidak ada anak.
tempNode = currNode;
currNode = NULL;
free(tempNode);
}
else{ // kalau anaknya 1.
*currNode = *tempNode;
free(tempNode);
}
}
else{
struct Node *tempNode = predecessor(currNode);
currNode->id = tempNode->id; // copy data dari temp ke curr.
strcpy(currNode->name, tempNode->name);
currNode->left = deleteNode(currNode->left, tempNode->id);
}
}
return currNode;
}
int search(struct Node *currNode, int id)
{
if(currNode == NULL)
return 0;
printInfix(currNode->left);
if(currNode->id == id)
return 1;
printInfix(currNode->right);
}
int main(){
struct Node *root = NULL;
root = insertNode(root, 20, "Bambang");
root = insertNode(root, 24, "Michelle");
root = insertNode(root, 22, "Budi");
root = insertNode(root, 18, "Jose");
root = insertNode(root, 18, "Yani");
printf("Infix :\n");
printInfix(root);printf("\n");
printf("Postfix :\n");
printPostfix(root);printf("\n");
printf("Prefix :\n");
printPrefix(root);printf("\n");
printf("Delete(Pop) :\n");
root = deleteNode(root, 22);
printInfix(root);printf("\n");
printf("Search() :\n");
if(search(root, 18) == 0)
{
printf("Not Found");
}
else
{
printf("Found");
}
}


{kind=link}
{kind=link}
{kind=link}
Comments
Post a Comment